


Business AI & Machine Learning – It’s Here to Stay
Artificial intelligence (AI) and machine learning (ML) use in the business world is rapidly growing as a way to drive greater business process efficiencies. According to a 2020 survey by Deloitte, 67% of the nearly 3,000 IT and business executives surveyed said their companies already had machine learning projects in place, while 97% were either using or planning to use machine learning within the next year.
In a 2021 report, Algorithmia discovered that companies are actively broadening the scope of what they are using AI and machine learning to accomplish, with a clear focus on the automation of business processes and customer experience.
So if you run a business, does this mean you should hurry to allocate some money in next year’s budget for a data scientist or two, maybe even start a new ML division in your IT department? Sure, you can. And maybe it will even work great for you. But like everything in life, it’s often not as simple as that.
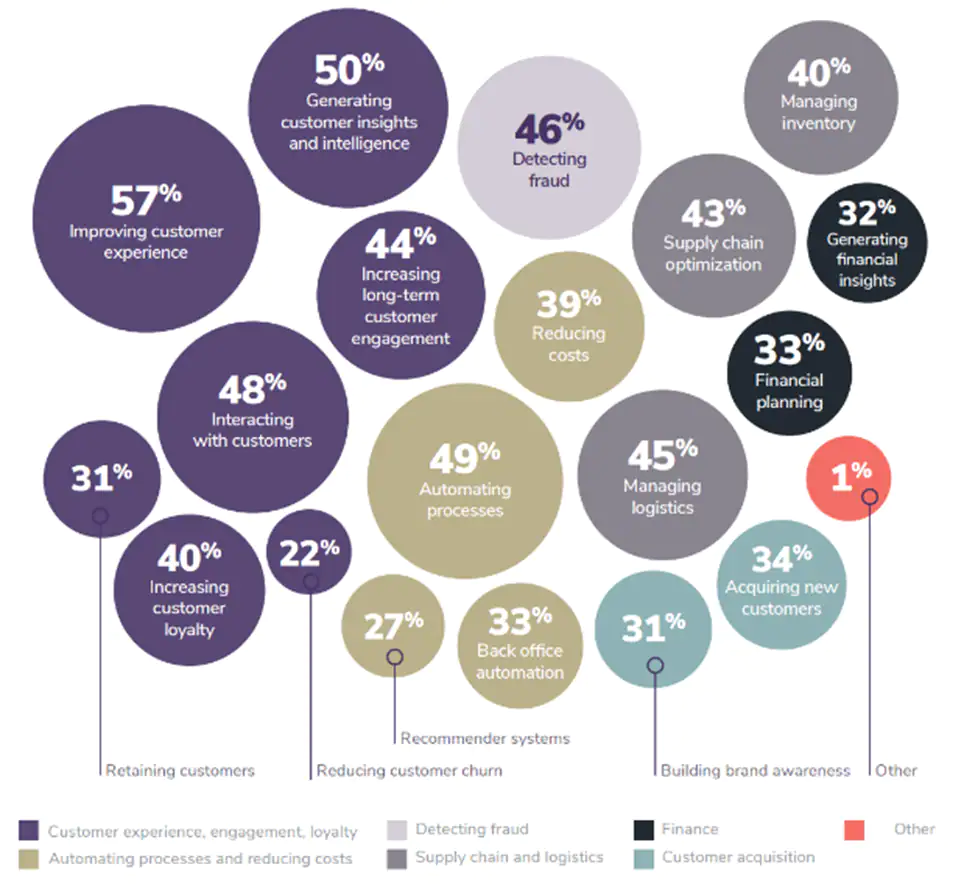
AI/ML Implementation Obstacles
Nearly all companies agree that AI and ML can be beneficial to their businesses if implemented successfully, but it is the successful implementation aspect that has its share of issues.
In May of 2019, Dimensional Research conducted a global survey of data scientists, AI experts, and stakeholders in large companies across 20 industries to determine their experiences with machine learning development projects. The report, Artificial Intelligence and Machine Learning Projects Are Obstructed by Data Issues, is loaded with interesting information. We highly recommend reading it all, but here are a few key takeaways:
- 78% of AI/ML projects stall at some stage before deployment
- 96% of enterprises encounter data quality and labeling challenges
- 63% have tried to build their own technology solutions
- 81% admit that training AI with data is more difficult than expected
The most common hurdle organizations face when deploying AI/ML solutions is around the data used to build and train the models. Companies frequently misunderstand or underestimate the data they already have and the utility it provides, how that data needs to be organized & labeled, and what data is needed to be acquired to properly build the required models. As a result, the projects cannot be implemented or are implemented poorly due to various data quality-related issues.
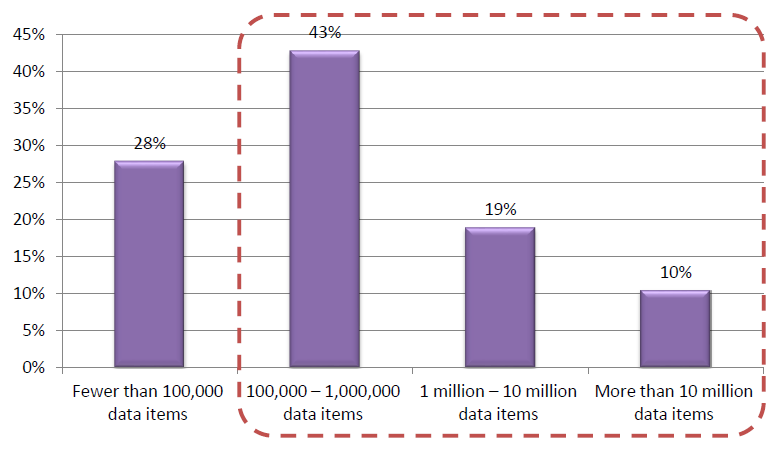
Most enterprises that do have machine learning teams in place, even very large organizations, have 10 or fewer people working on their AI/ML teams. 24% have fewer than 5. To deploy a machine learning model at the production level with confidence, a majority of ML projects require hundreds of thousands (if not millions) of labeled data items. These data science teams are not able to properly label all of the required training data in-house, and they often outsource these tasks to outside vendors, trying to receive at times complex annotations using outsourced lowest-cost labor. Often times this results in labeled data not achieving the accuracy needed to properly train the models, which results in a negative feedback loop – feeding bad data into an ML model results in poor model performance, which results in feeding more bad data into the model resulting in continued poor performance.
The research report Reshaping Business with Artificial Intelligence, published in the fall 2017 issue of the MIT Sloan Management Review, reveals another issue that stands out. The report shows that there is a lack of understanding by policy-makers and strategists regarding certain aspects of ML, particularly when it comes to the comprehension that generating business value from AI is directly linked with training AI algorithms:
“Many current AI applications start with one or more ‘naked’ algorithms that become intelligent only upon being trained (predominantly on company-specific data). Successful training depends on having well-developed information systems that can pull together relevant training data.”
In-House or Outsource Machine Learning Projects?
After reading about the difficulties companies may face in attempting to launch a successful machine learning project, it should be no surprise to hear that, as revealed by the Dimensional Research survey, 71% of organizations ultimately outsource ML project activities. Moreover, teams that outsource data labeling get projects into production faster.
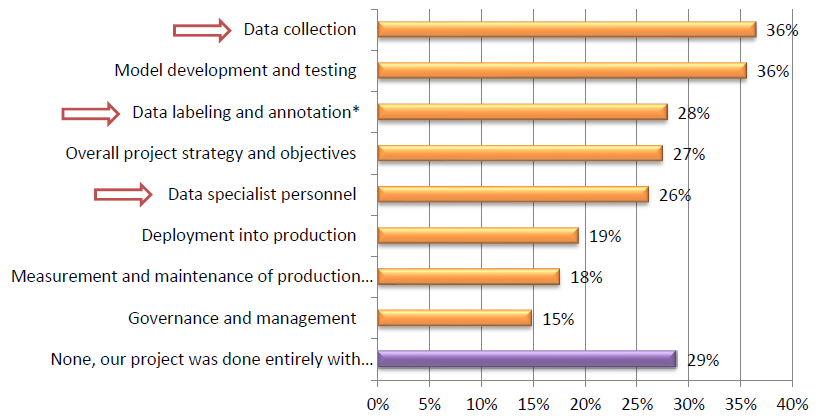
And of that 71% of organizations that outsourced ML activities, three of the top five external services utilized were related to training data.
TranscribeMe and Machine Learning
 TranscribeMe initially launched as a crowdsourced transcription company, and over the years we have evolved to provide all kinds of language services utilizing specially trained and managed worker teams. With AI and machine learning use cases, we provide a suite of data annotation & creation services that enable AI/ML teams to have the highest quality training data for their models. This is done through a combination of a proprietary worker and task management platform, paired with over two million freelancers registered to our platform.
TranscribeMe initially launched as a crowdsourced transcription company, and over the years we have evolved to provide all kinds of language services utilizing specially trained and managed worker teams. With AI and machine learning use cases, we provide a suite of data annotation & creation services that enable AI/ML teams to have the highest quality training data for their models. This is done through a combination of a proprietary worker and task management platform, paired with over two million freelancers registered to our platform.
The technology TranscribeMe has built enables for the rapid scaling of worker teams and ensures that workers are paired with the right tasks. Additionally, we have multiple quality assurance and review layers to ensure that output data is the highest possible quality. By automating many of these workforce management processes, we are able to deliver the best quality data quickly and at low cost.
What is critical to our success in being able to scale worker teams is our positive reputation in the work-from-home community. Our approach is to provide workers with resources, feedback, and treat them with respect. This helps to bring the best quality workers while maintaining competitive pricing, and TranscribeMe has received the highest ranking in the Fairwork Cloudwork rating.
The flexibility of the TranscribeMe platform along with the large pool of qualified workers allows us to provide a suite of different services for AI & ML use cases, including but not limited to the following:
- Transcription with complex timestamping and non-verbal annotations
- Translation of all kinds of NLP data in a variety of language pairs
- Text data annotations including sentiment, objects, relationships, and others
- Audio data creation in 10+ languages, most domains, and a wide range of demographics
Every AI/ML training use case has unique characteristics and requirements, and we’ve found the best process is to work directly with clients to determine the actual project needs so we can provide the lowest possible costs. All of our processes are customizable, and we can meet just about any requirement from geofencing worker teams to data deletion to custom formats. “One of the unique advantages we offer our clients is the ability to implement any style or requirement, no matter how unusual,” says TranscribeMe Operations Manager Emma Davies.
We would be happy to discuss your AI/ML training needs, please feel free to reach out to sales@transcribeme.com anytime for questions.
